Introduction
In the realm of machine learning, the veracity of the data is the utmost importance in the triumph of the models. Inappropriate data quality can result in wrong predictions, non -reliable ideas and global performance. Understanding the importance of data quality and becoming familiar with the techniques for discovering and facing data anomalies is important to build models of robust and reliable machine learning.

This article presents an overview of data anomalies, their impact on automatic learning and the techniques used to address them. In addition, through this article, readers will understand the fundamental role of data quality in machine learning and practical experience in detecting and mitigating data anomalies effectively.
This article has been published as part of the Data Science Blogathon.
What covers data anomalies?
Data anomalies, also known as data quality problems or irregularities, allude to any non -advance or aberrant features present within a data set.
These abnormalities may arise due to various factors, such as human falters, measurement inaccuracies, data corruption or system malfunction.
Identifying and rectifying data anomalies is of critical importance, as a result of which the reliability and precision of automatic learning models is ensured.
A variety of data anomalies
Data anomalies can be present in various forms. Highlights of data anomalies include:
- Missing data: Designation of cases in which the specific points or attributes of data are still not registered or incomplete.
- Duplicated data: Meaning the existence of identical or very similar data entries within the data set.
- Indicating instances: Where specific data points or attributes are still not registered or incomplete.
- Noise: Involving random variations or errors in data that can prevent analysis and modeling.
- Categorical variables: Covering inconsistent or ambiguous values within categorical data.
- Detecting and addressing these anomalies assumes the utmost importance in defending the integrity and reliability of the data used in machine learning models.
Discover and browse by missing data
The missing data can exert a remarkable impact on the precision and reliability of machine learning models. There are several techniques for managing missing data, such as:
import pandas as pd
# Dataset ingestion
data = pd.read_csv("dataset.csv")
# Identifying missing values
missing_values = data.isnull().sum()
# Eliminating rows with missing values
data = data.dropna()
# Substituting missing values with mean/median
data["age"].fillna(data["age"].mean(), inplace=True)This code example shows the load of a data set using pandas, missing values detection using the isnull () function, removing rows containing missing values using Dropna () and replacing values that are missing with average or medium -sized values using the Fillna () function.
Containing repetitive data
Repetitive data has the potential to bow the analysis and modeling results. It is essential to identify and expose duplicate entries in the data set. The following example elucidated duplicate data handling:
import pandas as pd
# Dataset ingestion
data = pd.read_csv("dataset.csv")
# Detecting duplicate rows
duplicate_rows = data.duplicated()
# Eliminating duplicate rows
data = data.drop_duplicates()
# Index reset
data = data.reset_index(drop=True)This code example demonstrates the detection and removal of duplicated rows using pandas. The duplicate () function () identifies duplicate rows, which can subsequently be deleted using the DROP_Duplicate () function. Finally, the index is reset using the reset_index () function, resulting in a pristine data set.
Manage the Outliers and the noise
Outliers and data noise have the potential to negatively affect the performance of machine learning models.
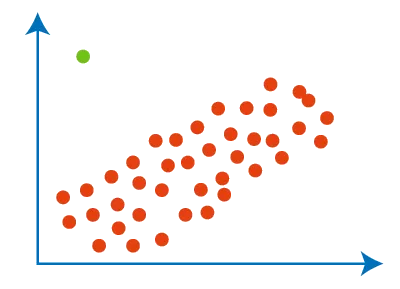
It is crucial to detect and manage these anomalies in a proper way. The subsequent example elucidated Outliers management using the Z -score method:
import numpy as np
# Calculating z-scores
z_scores = (data - np.mean(data)) / np.std(data)
# Establishing threshold for outliers
threshold = 3
# Detecting outliers
outliers = np.abs(z_scores) > threshold
# Eliminating outliers
cleaned_data = data[~outliers]This code example shows the calculation of z scores for data using numpy, the establishment of a threshold to identify outliers and the elimination of outliers of the data set. The resulting data set, Cleaned_Data, is devoid of outliers.
Solving the withundro of categorical variables
Categorical variables that have inconsistent or ambiguous values can introduce data quality predictions.
Handling categorical variables involve techniques such as standardization, single coding or ordinal coding. The subsequent example uses a single coding:
import pandas as pd
# Dataset ingestion
data = pd.read_csv("dataset.csv")
# One-hot encoding
encoded_data = pd.get_dummies(data, columns=["category"])In this example of code, the data set is using pandas and runs a unique coding through the Get_Dummies () function.
The resulting coded result will incorporate separate columns for each category, with binary values denoting the presence or absence of each category.
Preprocessing data for automatic learning
Preprocessing the data assumes importance in the management of data quality predication and preparing it for machine learning models.
You can perform techniques such as scales, normalization and selection of functions. The following example shows the preprociate data through Scikit-Learn.
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
# Feature scaling
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
# Feature selection
selector = SelectKBest(score_func=f_regression, k=10)
selected_features = selector.fit_transform(scaled_data, target)This code example illustrates the performance of the feature scale using StandardDSCALER () and functions using SELECTKBEST () from Scikit-Learn.
The resulting scaled result incorporates standardized features, while selected brakes include the most relevant features depending on the F-REGRESSION score.
Pioneering Function Engineering for Improved Data Quality
Characteristics engineering involves the creation of new characteristics or the transformation of existing ones to strengthen data quality and improve the performance of automatic learning models. The subsequent example shows an engineering of characteristics through pandas.
import pandas as pd
# Dataset ingestion
data = pd.read_csv("dataset.csv")
# Creation of a novel feature
data["total_income"] = data["salary"] + data["bonus"]
# Transformation of a feature
data["log_income"] = np.log(data["total_income"])In this code example, a new feature, total_Income, is created by adding the columns “salary” and “bonus”. Another feature, Log_Income, is generated by applying logarithm to the “Total_Income” spine using the Numpy Log () function. These characteristics engineering techniques increase data quality and provide complementary information to machine learning models.
Conclusion
In total, data abnormalities pose customary challenges in machine learning efforts. To acquire understanding on the different types of data anomalies and acquire the competition to detect and address them is essential to build models of learning of reliable and precise machines.
For the most part, adhering to the techniques and examples of code provided in this article, you can effectively address data quality predictions and improve the performance of machine learning efforts.
Key TakeaWoys
- Ensuring the quality of your data is crucial for reliable and precise automatic learning models.
- Poor quality of data, such as missing values, values and inconsistent categories, can adversely affect model performance.
- Use various techniques to clean and manage data quality problems. These include the management of missing values, elimination of duplicates, outliers management and the approach of categorical variables through techniques such as the coding of a fifth.
- Preprocessing the data Prepare for machine learning models. Techniques such as the characteristics scale, standardization and the selection of features help improve data quality and improve model performance.
- Function engineering involves creating new features or transforming existing ones to improve data quality and provide additional information to automatic learning models. This can lead to significant knowledge and more precise predictions.
The means shown in this article are not owned by Analytics Vidhya and are used at the discretion of the author.
Frequent questions
A. Data anomalies refer to observations or patterns that are significantly diverted from the standard or expected behavior. They can be data points, events or rare, unexpected or potentially indicative of errors, outliers or unusual patterns in the data set.
A. Automatic Learning (ML) is commonly used in anomalies detection to automatically identify anomalies in the data. ML models are trained with normal or non -anomalous data, and can then classify or mark instances that deviate from the patterns learned as potential anomalies.
A. An anomaly in machine learning refers to a point or data pattern that does not fit the expected behavior or the normal distribution of the data set. Anomalies may indicate unusual events, errors, fraud, malfunctions or other irregularities that may be of interest or concern.
A. There are several types of methods of detection of anomalies used in automatic learning, including statistical methods, grouping -based approaches, density estimation techniques, supervised learning methods and time series analysis. Each type has its own strengths and is suitable for different types of data and anomalies detection scenarios.
![]()
I am Tarak Ram, working as a machine learning interior in Antetern. I always have a curiosity to learn new things and interested in these emerging technologies, which takes me from an arts background to this advanced AI field.
I also teach machine learning on my YouTube channel and I always look forward to learning something new.