Ao aplicar técnicas modernas específicas de última xeración, os modelos de difusión estables fan posible xerar imaxes e audio. Difusión estable Funciona modificando os datos de entrada coa guía de entrada de texto e xerando novos datos de saída creativa. Neste artigo, veremos como xerar novas imaxes a partir dunha imaxe de entrada dada empregando difusores de modelos de profundidade a profundidade Pytorch Backend cun pipeline de rostro abrazado. Estamos a usar a cara de abrazos xa que fixeron unha xeración de imaxes fácil de usar usando un pipeline de difusión estable dispoñible.
Aprende máis: abrazando as funcións de canalización de transformadores de rostros
Obxectivos de aprendizaxe
- Comprende o concepto de difusión estable e a súa aplicación na xeración de imaxes e audio mediante técnicas modernas de última xeración.
- Gaña coñecemento dos compoñentes e técnicas clave implicadas na difusión estable, como modelos de difusión latente, autoencoders de denografía, autoencoders variacionais, bloques U-NET e codificadores de texto.
- Explora aplicacións comúns de modelos de difusión, incluíndo texto a imaxe, texto a video e conversións de texto a 3D.
- Aprende a configurar o ambiente para a difusión estable, incluíndo o uso de GPU e a instalación das bibliotecas e dependencias necesarias.
- Desenvolver habilidades prácticas para aplicar a difusión estable cargando e difundindo imaxes, creando solicitudes de texto para guiar a saída, axustando os niveis de difusión e entendendo as limitacións e retos asociados á xeración de imaxes mediante modelos de difusión estables.
Este artigo foi publicado como parte do Blogathon de ciencias de datos.
Que é unha difusión estable?
Os modelos de difusión estables funcionan como modelos de difusión latentes. Aprende a estrutura latente de entrada modelando como se difunden os atributos de datos a través do espazo latente. Pertencen á rede neuronal xeradora profunda. Considérase estable porque guiamos os resultados usando imaxes orixinais, texto, etc. Por outra banda, unha difusión inestable será imprevisible.
Os conceptos de difusión estable
A difusión estable usa a difusión ou xeración de imaxes latentes mediante un modelo de difusión estable (LDM), un modelo probabilístico. Estes modelos están adestrados como outros Modelos de aprendizaxe profunda. Aínda así, o obxectivo aquí é eliminar a necesidade de aplicacións continuas do procesamento de sinal que denotan unha especie de ruído nos sinais nos que a función de densidade de probabilidade é igual á distribución normal. Referímonos a isto como o ruído gaussiano aplicado ás imaxes de adestramento. Conseguimos isto mediante unha secuencia de autoencoders de denografía (DAE). Os DAES contribúen cambiando o criterio de reconstrución. Isto é o que altera a aplicación continua do procesamento de sinal. Inicialízase para engadir un proceso de ruído ao autoencoder estándar.
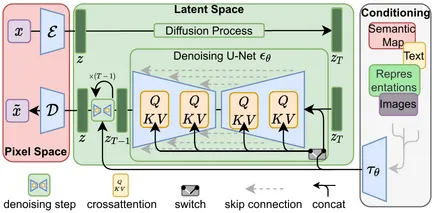
Nunha explicación máis detallada, a difusión estable consta de 3 partes esenciais: primeiro é o autoencoder variacional (VAE) que, en termos sinxelos, é unha rede neuronal artificial que funciona como modelos gráficos probabilísticos. A continuación está o bloque U-Net. Esta rede neuronal convolutiva (CNN) foi desenvolvida para a segmentación de imaxes. Por último é a parte do codificador de texto. Un clip adestrado Vit-L/14 codificador de texto trata isto. Xestiona as transformacións do texto solicita nun espazo de incrustación.
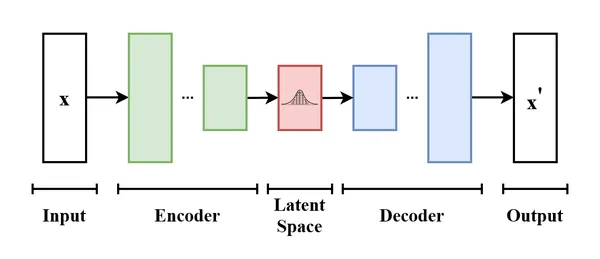
O codificador VAE comprime os valores do espazo do píxel de imaxe nun espazo latente dimensional menor para realizar a difusión da imaxe. Isto axuda á imaxe a non perder detalles. Está representado de novo en imaxes pixeladas.
Aplicacións comúns de difusión
Vexamos rapidamente tres zonas comúns onde se poden aplicar modelos de difusión:
- Texto a imaxe: Este enfoque non usa imaxes senón unha peza de texto “rápido” para xerar fotos relacionadas.
- Texto a Videos: Os modelos de difusión úsanse para xerar vídeos fóra de solicitudes de texto. A investigación actual usa isto en medios para facer fazañas interesantes como crear vídeos de anuncios en liña, explicar conceptos e crear vídeos de animación curtos, vídeos de cancións, etc.
- Texto a 3D: Esta xeración de imaxes estable mediante un enfoque de difusión estable converte o texto de entrada en imaxes 3D.
A aplicación de difusores pode axudar a xerar imaxes gratuítas sen plaxio. Isto proporciona contido para os teus proxectos, materiais e incluso marcas de mercadotecnia. En lugar de contratar a un pintor ou fotógrafo, podes xerar as túas imaxes. En lugar dun artista de voz en off, podes crear o teu audio único. Agora vexamos a xeración de imaxes a imaxe.

Lea tamén: Trae a vida os garabatos: modelo de AI de código aberto meta
Configuración do ambiente
Esta tarefa require GPU e un bo ambiente de desenvolvemento como procesar imaxes e gráficos. Espérase que teña GPU dispoñible se desexa seguir xunto con este proxecto. Podemos usar Google Colab xa que ofrece un ambiente e GPU adecuados e podes buscalo en liña. Siga os pasos seguintes para involucrar a GPU dispoñible:
- Vai ao Tempo de execución pestaña cara á parte superior dereita.
- Despois de seleccionar o tempo de execución, faga clic en Cambiar o tipo de tempo de execución opción.
- Logo seleccione GPU como acelerador de hardware desde a opción despregable.
Podes atopar todo o código activado GitHub.
Importación de dependencias
Hai varias dependencias ao usar o pipeline de Huggingface. Primeiro comezaremos a importalos ao noso entorno do proxecto.
Instalación de bibliotecas
Algunhas bibliotecas non están preinstaladas en Colab. Necesitamos comezar instalándoos antes de importar deles.
# Installing required libraries
%pip install --quiet --upgrade diffusers transformers scipy ftfy# Installing required libraries
%pip install --quiet --upgrade accelerateImos explicar as instalacións que fixemos anteriormente. En primeiro lugar son os difusores, transformadores, Scipye ftfy. Scipy e ftfy son estándar Python Bibliotecas que empregamos para tarefas python diarias. A continuación explicaremos as novas bibliotecas importantes.
Difusores: Difusers é unha biblioteca dispoñible abrazando a cara para obter unha imaxe ben adestrada para imaxes modelos de difusión estables para xerar imaxes. Imos usalo para acceder ao noso pipeline e outros paquetes.
Transformadores: Os transformadores conteñen ferramentas e API que nos axudan a reducir os custos de formación desde cero.
# Backend
import torch
# Internet access
import requests
# Regular Python library for Image processing
from PIL import Image
# Hugging face pipeline
from diffusers import StableDiffusionDepth2ImgPipelineStatedifusionDePth2imgpipeline é a biblioteca que reduce o noso código. Todo o que debemos facer é pasar unha imaxe e un aviso que describe as nosas expectativas.
Instantalando os difusores pre-adestrados
A continuación, só facemos unha instancia do difusor pre-adestrado que importamos anteriormente e asignámolo á nosa GPU. Aquí isto é Cuda.
# Creating a variable instance of the pipeline
pipe = StableDiffusionDepth2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-depth",
torch_dtype=torch.float16,
)
# Assigning to GPU
pipe.to("cuda")Preparación de datos de imaxe
Imos definir unha función para axudarnos a comprobar imaxes de URL. Podes saltar este paso para probar unha imaxe que tes localmente. Monte a unidade en Colab.
# Accesssing images from the web
import urllib.parse as parse
import os
import requests
# Verify URL
def check_url(string):
try:
result = parse.urlparse(string)
return all([result.scheme, result.netloc, result.path])
except:
return FalsePodemos definir outra función para usar a función check_url para cargar unha imaxe.
# Load an image
def load_image(image_path):
if check_url(image_path):
return Image.open(requests.get(image_path, stream=True).raw)
elif os.path.exists(image_path):
return Image.open(image_path)Imaxe de carga
Agora, necesitamos unha imaxe para difundir noutra imaxe. Podes usar a túa foto. Neste exemplo, estamos a usar unha imaxe en liña para a comodidade. Non dubide en usar o seu URL ou imaxes.
# Loading an image URL
img = load_image("https://img.freepik.com/free-photo/stacked-tomatoes_1353-262.jpg?w=740&t=st=1683821147~exp=1683821747~hmac=708f16371d1e158d76c8ea5e8b9790fb68dc75009750b8328e17c21f16d36468")
# Displaying the Image
img
Creando solicitudes de texto
Agora temos unha imaxe utilizable. Vexamos agora algunha imaxe para imaxes de difusión estable. Para conseguilo, envolvemos as solicitudes ás imaxes. Trátase de conxuntos de textos con palabras clave que describen as nosas expectativas da difusión. En lugar de xerar unha nova imaxe aleatoria, podemos usar solicitudes Para guiar a saída do modelo.
Teña en conta que fixamos a forza a 0,7. Esta é unha media. Ademais, teña en conta o negativo_prompt está configurado en ningún. Miraremos isto máis tarde.
# Setting Image prompt
prompt = "Some sliced tomatoes mixed"
# Assigning to pipeline
pipe(prompt=prompt, image=img, negative_prompt=None, strength=0.7).images[0]
Agora podemos continuar con este paso en novas imaxes. O método segue sendo;
Cargando a imaxe a difundir e
Creación dunha descrición de texto da imaxe de destino.
Podes crear algúns exemplos por conta propia.
Creando avisos negativos
Outro enfoque é crear un aviso negativo para contrarrestar a saída prevista. Isto fai que o gasoduto sexa máis flexible. Podemos facelo asignando un aviso negativo ao negativo_prompt variable.
# Loading an image URL
img = load_image("https://img.freepik.com/free-photo/stacked-tomatoes_1353-262.jpg?w=740&t=st=1683821147~exp=1683821747~hmac=708f16371d1e158d76c8ea5e8b9790fb68dc75009750b8328e17c21f16d36468")
# Displaying the Image
img
# Setting Image prompt
prompt = ""
n_prompt = "rot, bad, decayed, wrinkled"
# Assigning to pipeline
pipe(prompt=prompt, image=img, negative_prompt=n_prompt, strength=0.7).images[0]
Axuste do nivel de difusión
Podes preguntar sobre alterar canto cambia a nova imaxe desde a primeira. Podemos conseguilo cambiando o nivel de forza. Observaremos o efecto de diferentes niveis de forza na imaxe anterior.
En forza = 0,1
# Setting Image prompt
prompt = ""
n_prompt = "rot, bad, decayed, wrinkled"
# Assigning to pipeline
pipe(prompt=prompt, image=img, negative_prompt=n_prompt, strength=0.1).images[0]
Sobre a forza = 0,4
# Setting Image prompt
prompt = ""
n_prompt = "rot, bad, decayed, wrinkled"
# Assigning to pipeline
pipe(prompt=prompt, image=img, negative_prompt=n_prompt, strength=0.4).images[0]
En forza = 1.0
# Setting Image prompt
prompt = ""
n_prompt = "rot, bad,decayed, wrinkled"
# Assigning to pipeline
pipe(prompt=prompt, image=img, negative_prompt=n_prompt, strength=1.0).images[0]
A variable de forza permite traballar sobre o efecto da difusión na nova imaxe xerada. Isto fai que sexa máis flexible e axustable.
Limitacións dos modelos de difusión
Antes de chamalo envoltorio sobre a difusión estable, hai que entender que se pode afrontar algunhas limitacións e retos con estes oleoductos. Cada nova tecnoloxía sempre ten algúns problemas ao principio.
- Adestramos o modelo de difusión estable en imaxes con resolución 512 × 512. A implicación é que cando xeramos novas fotos e desexar dimensións superiores a 512 × 512, a calidade da imaxe tende a degradarse. Aínda que, hai un intento de resolver este problema actualizando versións máis altas do modelo de difusión estable onde podemos xerar imaxes pero a resolución 768 × 768. Aínda que a xente intenta mellorar as cousas, sempre que haxa unha resolución máxima, o caso de uso limitará principalmente a impresión de grandes pancartas e folletos.
- Adestrando o conxunto de datos na base de datos de Laion. É unha organización sen ánimo de lucro que ofrece conxuntos de datos, ferramentas e modelos con fins de investigación. Isto demostrou que o modelo non podía identificar as extremidades humanas e as caras ricamente.
- A imaxe estable para a difusión estable nunha CPU pode funcionar nun tempo factible que vai desde uns segundos ata uns minutos. Isto elimina a necesidade dun ambiente de alta computación. Só pode ser un pouco complexo cando se personaliza o pipeline. Isto pode esixir RAM e procesador elevados, pero a canle dispoñible leva menos complexidade.
- Por último, é a cuestión dos dereitos legais. A práctica pode sufrir asuntos legais facilmente xa que os modelos requiren vastas imaxes e conxuntos de datos para aprender e funcionar ben. Unha instancia é a demanda de xaneiro de 2023 de tres artistas por infracción de dereitos de autor contra Estabilidade ai, Midjourneye Deviantart. Polo tanto, pode haber limitacións para construír libremente estas imaxes.
Conclusión
En conclusión, mentres o concepto de difusores é de punta, o pipeline de cara abrazado facilita a integración nos nosos proxectos cun código sinxelo e moi directo. Usar solicitudes nas imaxes fai posible establecer e traer unha imaxe imaxinaria á difusión. Ademais, a variable de forza é outro parámetro crítico. Axúdanos co nivel de difusión. Vimos como xerar novas imaxes a partir de imaxes.
Takeaways clave
- Ao aplicar técnicas de última xeración, os modelos de difusión estables xeran imaxes e audio.
- As aplicacións típicas de imaxe para a difusión estable de imaxe inclúen texto a imaxe, texto a video e texto a 3D.
- Statedifusion Profundh2imgpipeline é a biblioteca que reduce o noso código, polo que só necesitamos pasar unha imaxe para describir as nosas expectativas.
Aprende máis: Pytorch | Comezar con Pytorch
Xeración de imaxes mestras co noso Difusión estable con abrazo de cara. Aprende a crear imaxes impresionantes a partir de solicitudes de texto e de entrada de imaxes con facilidade.
Ligazóns de referencia
Os medios mostrados neste artigo non son propiedade de Analytics Vidhya e úsanse a criterio do autor.
Preguntas frecuentes
A. A difusión estable permite aos usuarios xerar imaxes de alta calidade perfeccionándoas iterativamente mediante procesos de difusión. Esta técnica mellora a calidade e o realismo da imaxe ao longo do tempo, tornándoo adecuado para diversas aplicacións creativas e artísticas.
R. Si, a difusión estable é de código aberto e está dispoñible de balde. Os usuarios poden acceder e utilizar o modelo sen ningún custo, facilitando a experimentación e o desenvolvemento no campo da xeración e mellora de imaxes.
A. Si, a difusión estable pode xerar contido NSFW (non seguro para o traballo) xa que permite aos usuarios controlar e manipular os procesos de xeración de imaxes. Non obstante, deben seguir consideracións éticas e directrices á hora de crear tal contido.
A. Para comezar a traballar con difusión estable, pode instalar as bibliotecas e dependencias necesarias, como Pytorch e o marco de difusión estable. A continuación, explora tutoriais e documentación dispoñibles en liña para comprender as súas funcionalidades e comezar a experimentar con tarefas de xeración de imaxes.
![]()
Son un enxeñeiro de AI cunha profunda paixón pola investigación e resolvendo problemas complexos. Proporciono solucións AI aproveitando grandes modelos de idiomas (LLMs), Genai, modelos de transformadores e difusión estable.